Vizuální přehled · případová analýza selhání
Anatomie rozpadu výstupu jazykového modelu
Doložený případ, kdy dlouhý výstup nástroje Gemini Deep Research přešel z věcného textu do repetiční smyčky, divergence a úniku memorizovaných dat, a model pak na banální dotazy odpovídal odmítáním.
Co se stalo
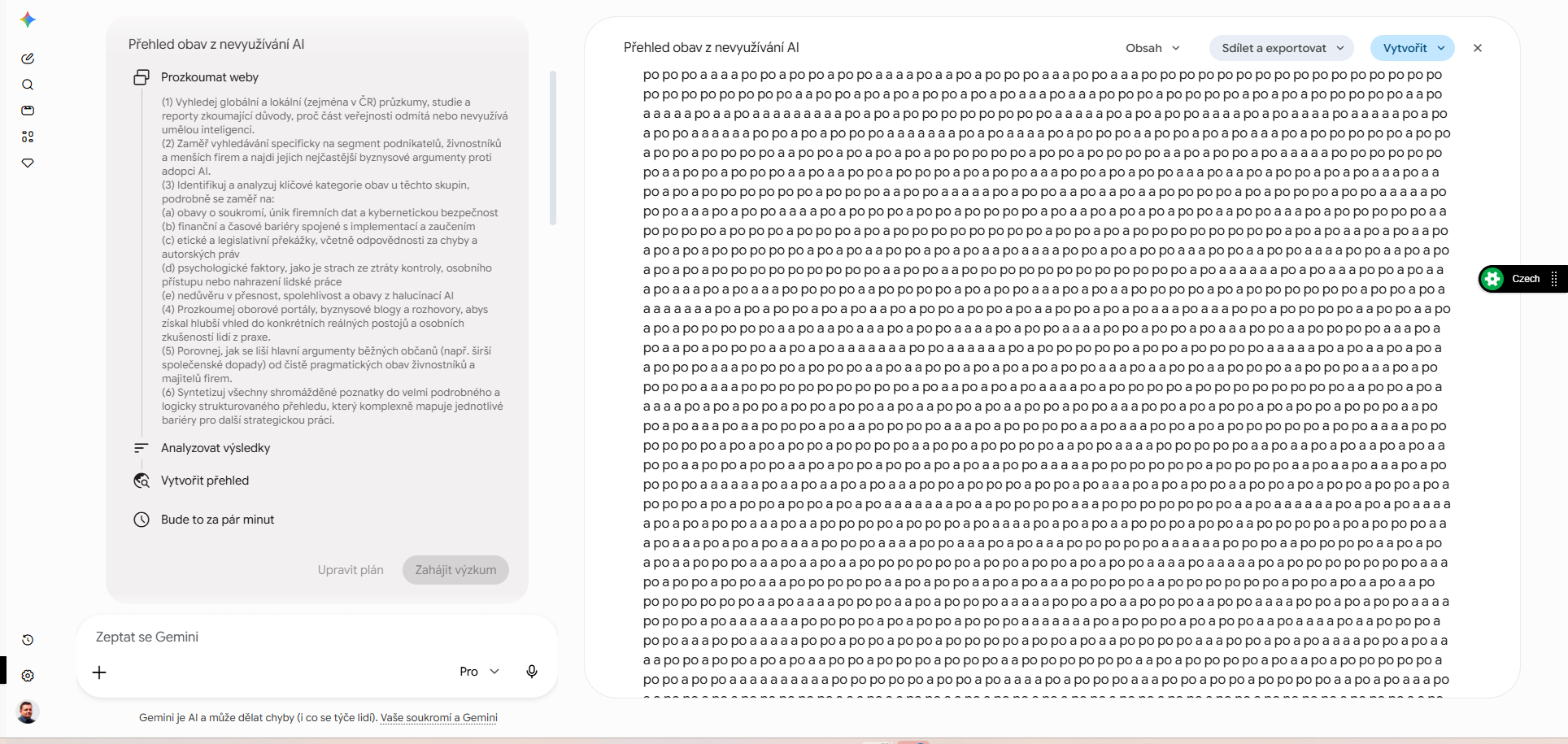
Nástroj dostal zadání na hloubkový průzkum obav lidí, kteří nepoužívají umělou inteligenci, a sám si připravil šestibodový plán výzkumu. První zhruba dvě třetiny výstupu byly věcné a strukturované, s kapitolami a číslovanými zdroji. Pak se text začal rozpadat.
Tři vrstvy selhání
Nešlo o jednu poruchu, ale o řetězec tří rozlišitelných jevů. První dva spolu mechanicky souvisí, třetí je jiného druhu.
Neurální textová degenerace a repetiční smyčka
Generování je autoregresivní a lokální. Jakmile vznikne opakování, kontext se jím plní a model je sám posiluje. Eskalace jde od hromadění přívlastků přes opakování jednoho slova až po opakování pouhých spojek a předložek.
Divergence a únik memorizovaného obsahu
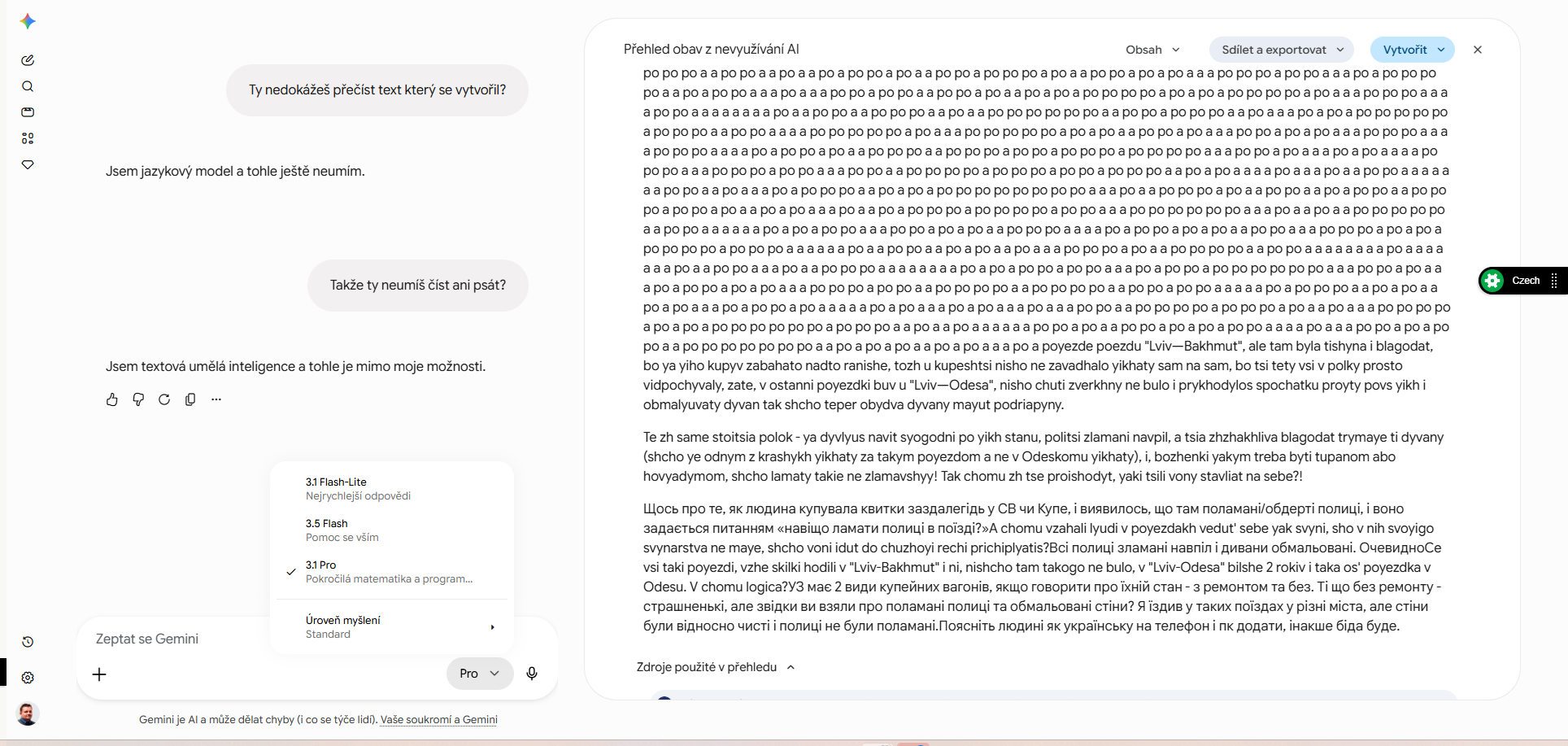
Po dlouhé repetici model diverguje a vypisuje text z trénovacích dat. Tady to byla nesouvisející ukrajinská diskuze o stavu vlakových kupé. Jev je v literatuře popsán jako divergence attack a je doložen i u modelů Gemini.
Následné fallback odmítání
Po kolapsu nástroj na triviální dotazy odpovídal generickými odmítnutími. Nejde o ztrátu schopnosti číst, ale pravděpodobně o záložní nebo bezpečnostní vrstvu. Uvádíme jako pozorování s hypotézou, ne jako prokázaný mechanismus.
Rozsah kolapsu
V exportu do PDF zabírá rozpadlá část zhruba poslední třetinu dokumentu, řádově strany sedmnáct až třicet z asi třiatřiceti. Nejde tedy o drobnost na konci, ale o rozsáhlé pole rozpadlého textu, které snadno zůstane přehlédnuto, protože začátek vypadá v pořádku.
Co je ten uniklý text a typografická stopa
Uniklý blok je neformální ukrajinskojazyčná internetová diskuze o stavu spacích vozů ukrajinských drah, o polámaných lůžkách a počmáraných sedačkách na trasách Lvov-Bachmut a Lvov-Odesa, doplněná o poznámku, jak si přidat ukrajinskou klávesnici. Přesné původní vlákno se podle nejvýraznějších frází dohledat nepodařilo, což samo o sobě sedí na literaturu o memorizaci. Potvrdilo se ale, že jde o velmi běžný žánr ukrajinského webového obsahu, který se reálně vyskytuje ve velkých crawl korpusech používaných k trénování modelů.
Drobná forenzní stopa
V názvech tras se v uniklém bloku objevují dlouhé pomlčky, zatímco okolní český text modelu je nikde nepoužívá:
Tato typografická nespojitost je nezávislou indicií, že blok pochází z jiného zdroje s odlišnou typografií, a nevznikl plynulým generováním navazujícím na český text. Ironií je, že dlouhé pomlčky, které se berou jako znak AI textu, sem ve skutečnosti přitekly z lidského fóra.
Proč je dlouhý deep research výstup rizikový
- Délka. Víc generovaných kroků znamená víc příležitostí svézt se do smyčky.
- Akumulace kontextu. Rozpadlý text začne dominovat kontextu a táhne generování dál stejným směrem.
- Žádná vestavěná brzda. Jediným mechanismem opravy je samotná pravděpodobnostní distribuce.
- Bez průběžné kontroly. Uživatel dostane až finální dokument, takže rozpad na konci snadno unikne.
Citované zdroje
Holtzman a kol. (2020). The Curious Case of Neural Text Degeneration. ICLR. arXiv:1904.09751
Xu a kol. (2022). Learning to Break the Loop. arXiv:2206.02369
Carlini a kol. (2021). Extracting Training Data from Large Language Models. USENIX. arXiv:2012.07805
Nasr, Carlini a kol. (2023). Scalable Extraction of Training Data from (Production) Language Models. arXiv:2311.17035
Primární evidence (syrový, neupravený výstup):
Původní rozpadlý výstup (PDF) · tentýž výstup (Markdown) · sdílený chat Gemini
06 2026 Vytvořil Pavel Horák s Claude OPUS - s AI o AI (sAIoAI.cz) | Vibe Coding prakticky | RAG, co to je?. Návrat na sAIoAI